







新闻中心 
什么样的智算网络方案才是客户真正想要的?
 2025-11-21
2025-11-21 浏览次数:
次
浏览次数:
次 返回列表
返回列表这些年,围绕智算网络技术方案,业界逐渐形成了两大主流方向:一种是以“GPU + Infiniband(IB)”为代表的私有方案流派;还有一种,是以“魔改”高性能以太网(RoCEv2)为代表的开放方案流派。与此同时,国内算力需求持续快速增长,国产算力生态加速崛起,形态更加多元,出现了更多不同品牌的 GPU、网卡和整机系统。在这种多星空体育 星空体育平台元化背景下,行业对于“更开放、更易演进、可持续”的网络底座需求也变得愈发迫切。
正因如此,“魔改以太网”开放方案的阵营正在不断扩大。这条技术路线不仅保持了成本、生态方面的固有优势,在性能、可靠性、兼容性等关键指标上持续逼近乃至赶超IB。对于国内目前如火如荼的智算基础设施建设来说,这无疑是一个重大利好。
前段时间,新华三推出了一个很有特色的创新架构智算方案,名字叫做DDC,吸引了整个行业的关注。这个方案,就属于刚才说的开放方案流派。
说到DDC,可能很多专业读者会首先想到业界最早提出的“分布式解耦机框(Disaggregated Distributed Chassis)”。如果它是DDC 1.0,那么新华三推出的DDC架构,则是在DDC 1.0基础上的演进升级,全称叫Diversified Dynamic-Connectivity,多元动态联接。它同样属于分布式解耦机框的技术路线,但引入了多项关键技术创新,在传输性能、连接规模、开放解耦、运维简化等方面都有了巨大的改进提升。

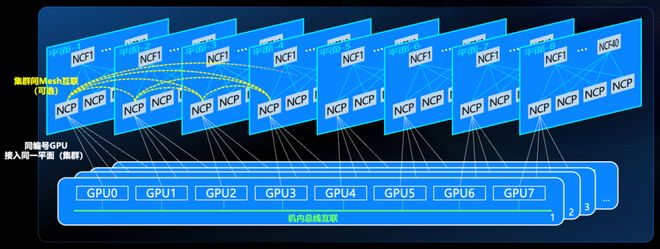
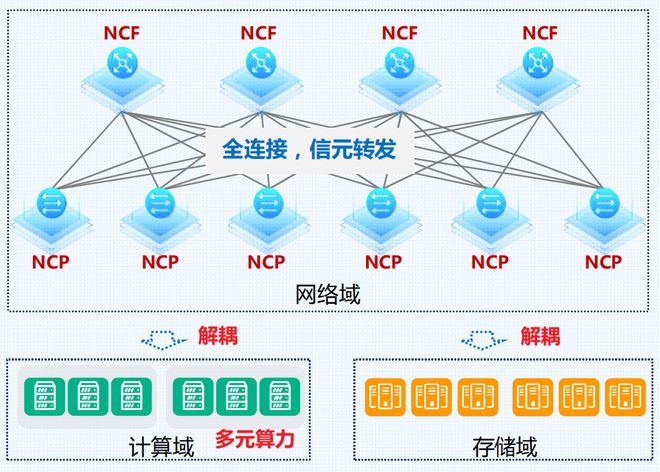
高带宽+大规模新华三的DDC方案包括NCP(网络处理单元)和NCF(网络交换单元)两层,通过Spine-Leaf叶脊架构进行全连接。NCP相当于业务线卡,NCF相当于交换网板,都是独立工作的盒型形态。

方案对应到新华三的具体产品,是H3C S12500AI系列交换机。NCF有一款H3C S12500AI-NCFN。NCP有两款,分别是H3C S12500AI-18EP20EP-NCPN、H3C S12500AI-36DH20EP-NCPN。

NCP和NCF的端口都支持800G,完全可以满足当前主流网卡形态的接入需求,带宽妥妥够。
规模方面,也很容易计算。单POD组网(DDC单集群)下,800G信元端口可以分为两个400G,也就是支持40个NCF和256个NCP,总共支持256(接入设备)*36(接入端口)=9216个端口(400G)。如果是800G的线个端口。
这个端口数量,足够支撑国内绝大多数的智算集群应用。如果要搞万卡集群,就可以采用多POD组网(DDC多集群),最大可支持8个POD,也就是73728个400G端口(或36864个800G端口)。
零拥塞+零波动接下来,我们来看最关键的无损传输。也就是说,当智算网络处于高流量负荷状态的时候,会不会出现丢包、抖动和拥塞。
众所周知,AIGC大模型训练业务对网络丢包极为敏感,轻则导致吞吐效率降低,重则将使训练任务中断。无论是哪一种,都会严重影响算力集群的训练周期和成本。
大模型训练场景的流量特点,概括来说,就是大而且杂。因为训练包括多种方式(例如DP数据并行、PP流水并行、TP张量并行、EP专家并行),每种方式的流量模型不一样。有的带宽高(低),有的流数多(少),还经常会高并发、突发。
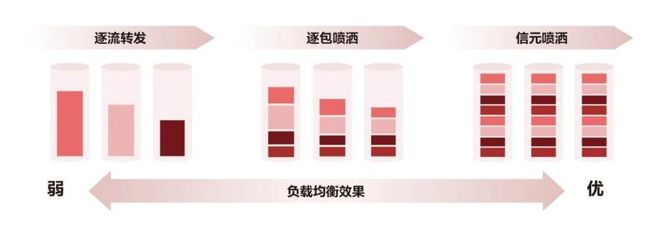
传统的ECMP(等价多路径路由)等负载均衡机制根本无法应对这种复杂流量特征,流量容易被哈希到同一链路,产生拥塞。
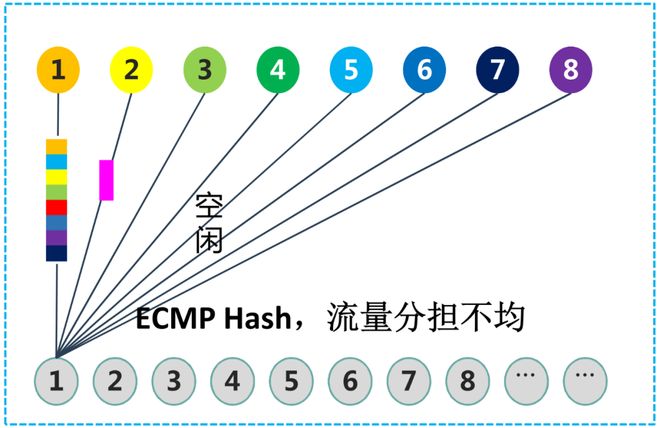
新华三DDC方案的做法,是网卡(GPU)侧的数据流进入NCP后,切割为等长字节的信元。然后,将这些信元动态、均衡地喷洒到内部交换网络(NCF)的所有链路上。在信元到达出口NCP时,再进行重组。
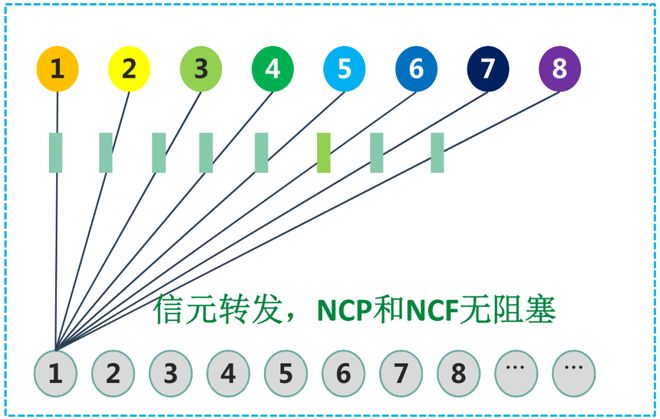
下图,是传统非DDC的RoCE方案的拥塞案例,基于PCF(优先级流控制)+ECN(显性拥塞通知)机制。
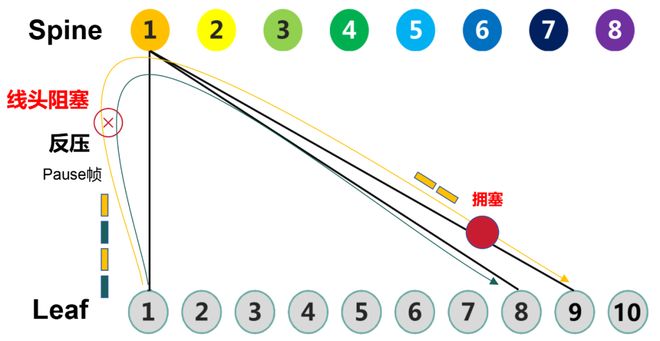
具体来说,当Spine1到Leaf9之间的链路(黄色线)出现拥塞时,Spine1会逐层向上反压,向Leaf1发PFC帧。这就会导致Leaf1和Spine1之间端口的相关队列全部被压住。这就会影响Spine1到其它Leaf(例如绿色线)的流量。这就是线头阻塞问题。
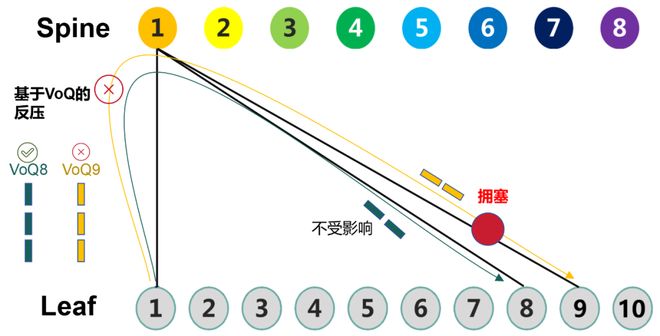
DDC方案的VoQ,是在入口设备上基于不同出端口维护的队列。当Spine1到Leaf9之间的链路出现拥塞时,只影响基于Leaf9的VoQ队列。其它VoQ队列(例如Leaf1到Leaf8)并不星空体育 星空体育平台受影响。这就避免了线头阻塞的问题,实现了精准反压。
VoQ解决了线头阻塞问题。那么确定性的拥塞控制,又是如何实现的呢?这就需要Credit授权控制转发机制的配合。
可以将Credit理解为令牌。当入向要往出向进行转发时,会先发授权请求。当出向的带宽可以保证报文转发的时候,出口NCP才会给入口NCP发Credit授权回应,允许流量推送。
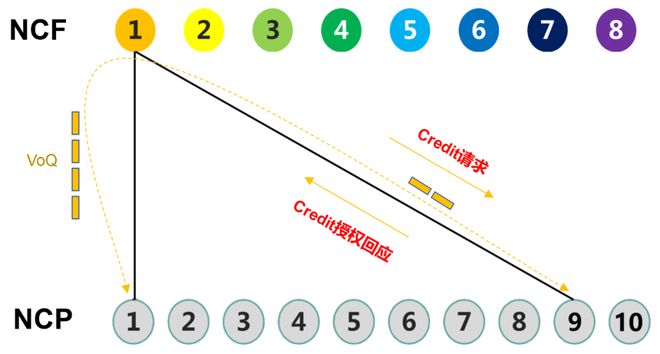
Credit有点像餐厅的叫号系统。只有叫号了,才允许进入,就可以避免拥塞。
在以信元转发为核心的负载均衡机制和基于“Credit + VoQ”的确定性拥塞控制机制的共同加持下,新华三DDC方案能够实现链路利用率100%的负载均衡效果,且充分吸收突发流量,彻底消除DDC网络内部的拥塞。
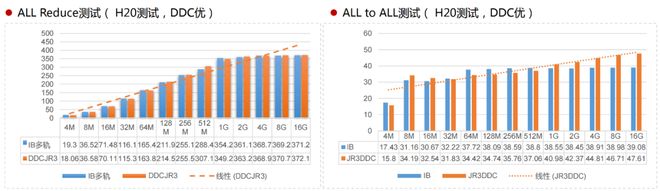
经权威机构测试验证,新华三DDC方案的带宽利用率丝毫不亚于InfiniBand网络。
在8台服务器64张英伟达H20 GPU卡,进行NCCL-Test对比测试。All Reduce场景下,DDC性能与IB基本持平。16G数据时,DDC比IB提升了0.27%。All-to-All场景下,256M以下数据对比IB无提升效果。1G以上数据时,DDC性能提升明显。16G数据时,比IB提升了21.74%。这说明,数据量越大,DDC的优势越明显。
网卡解耦+多元异构新华三DDC作为分布式机框,实现了“物理上的分体、逻辑上的整体”。它就像一个“超级交换机”,前面提到的信元切割、重组,还有VoQ+Credit技术,都是在其内部完成的,不需要网卡的参与。
此外,DDC基于信元的拥塞管理和负载均衡是独立于IP转发域的。DDC对不同的流量模型和特征都不敏感。设备接入DDC后,网卡侧也不需要进行专门的调优。
极简部署+极简运维新华三DDC方案需要联接海量设备和异构算力,业务流量大,流量特征复杂。这给整个系统的运维带来了很大的挑战。
对此,新华三推出了AD-DC智算版智能管控分析平台。该平台预设了DDC开局模板,具备一键自动上线功能,设备即插即用,无需复杂调优,从而大幅简化部署流程,可以实现天级快速交付。
通过平台,还可以对整个DDC网络进行可视化管理,直接掌控全网架构。平台也可以自动检测设备间的链路状态,如果发现断连、错连等异常,就会及时告警,实现可视化定位。
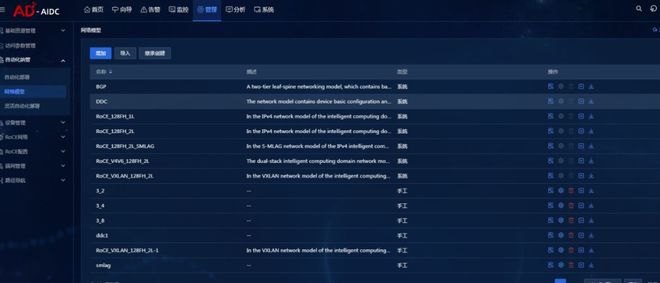
AD-DC智算版智能管控分析平台引入了AI算法进行运维。系统会实时采集设备端口流量、Pause帧等关键指标,结合AI算法进行深度分析,精准识别网络拥塞、异常流量等潜在故障。
在芯片丢包、光模块故障等方面,AD-DC都有快速诊断能力,可以大幅降低系统运行风险,减少对训练任务造成的影响。
行业里的智算网络方案分为封闭(私有闭源)和开放两种。业界有一些可提供GPU和网络方案的厂商,就会通过集合通信库(CCL)将二者进行捆绑,迫使客户只能选择整套解决方案。
DDC的控制平面使用标准的BGP EVPN协议,不但实现网元之间自协商、自组网,降低了配置复杂程度,更能支持不同厂商的NCP/NCF实现异构组网。
这几年,新华三一直坚持这个路线年,他们携手合作伙伴,发布了OSF(Open Schedule Fabric,开放调度网络)协议网络架构,分别在需求场景分析、方案框架定义、技术方案落地等三个方面提交了多篇标准议案,得到了IETF组织的认可。这个架构将调度式网络架构与传统以太网络结合,能够达到均衡利用网络资源、故障快速切换等优化目标。
正如前面所说,国内的智算建设具有多元化的特点。所以,开放生态显然更适合当下的发展趋势。往小了说,开放生态对用户有利,降低了使用智算算力的技术难度,也减少了成本投入。往大了说,我们国家智算基础设施的建设布局,以及整个智算产业和生态的健康发展,都会随之受益。
智算中心的总投资中,智算网络投资占比仅为10%。10%的智算网络投资将会撬动30%以上算力效能提升。这是一个非常划算的买卖。
这充分说明,在智算时代,网络已不再是单纯的“联接”。它与计算深度融合,可以发挥“算力×联接”的倍增效应。
新华三开了一个好头,通过DDC架构创新,解决了智算网络在超大规模、极致性能与生态适配方面的难题,不仅为国产化方案树立了标杆,也为全球用户提供了新的选项。
